7 Key Insights into Kubernetes v1.36's PSI Graduation to GA
Pressure Stall Information (PSI) metrics have been a hidden gem in the Linux kernel since 2018, offering a precise view of resource contention long before old school numbers flash red. With Kubernetes v1.36, PSI graduates to General Availability, giving every cluster operator a stable, low‑overhead lens into CPU, memory, and I/O bottlenecks. In this article, we break down seven crucial things you need to know about this milestone—from what makes PSI different to the rigorous performance tests that proved it production‑ready. Whether you're tuning high‑density workloads or troubleshooting mysterious latency, these insights will help you leverage PSI like a pro.
1. PSI Measures Stalled Tasks, Not Just Raw Utilization
Traditional utilization metrics tell you how much of a resource is being used—say 70% CPU. But that number can be dangerously deceptive. You might see 70% while critical tasks are queued for seconds. PSI flips the script by reporting the percentage of time tasks are actually stalled, waiting for a resource. This “stall time” reveals hidden contention that utilization hides. For example, a node at 85% memory may look fine, but PSI can show that I/O waits are crippling throughput. In v1.36, these signals are now available at the node, pod, and container levels through a stable API, giving you the high‑fidelity data needed to catch saturation before it becomes an outage.
2. Cumulative Totals and Moving Averages Provide Dual Insight
PSI exposes two complementary views of resource pressure. Cumulative totals show the absolute time (in microseconds) that tasks have spent stalled since boot. This gives you the big‑picture, long‑term cost of contention. Moving averages smooth the data over 10‑second, 60‑second, and 300‑second windows, letting you distinguish a transient spike from sustained tension. Together, they help operators decide when to scale or throttle. For instance, a 60‑second average of 2% CPU pressure is likely harmless, but a 10‑second average of 15% might indicate an immediate bottleneck. In v1.36, both metrics are exposed via the same Prometheus‑friendly endpoints you already use, making integration seamless.
3. Why Traditional Utilization Metrics Fall Short
Relying solely on CPU or memory usage can lead to false confidence. Consider a node running a batch job and a latency‑sensitive web server. The CPU may hover at 60%, but if the kernel is constantly preempting the web server to serve the batch job, the web server experiences severe latency. Utilization metrics miss this because they aggregate all CPU time. PSI, on the other hand, tracks how long tasks are stalled on the scheduler. That stall time is the real measure of contention. In production, this difference can mean the difference between a healthy cluster and one where users complain of slow responses while dashboards show everything “green.”
4. SIG Node Put PSI Through Rigorous Performance Testing
A common fear with new telemetry is the resource overhead it adds. To address this, SIG Node conducted extensive validation on high‑density workloads (80+ pods) across various machine types. The team designed two scenarios to isolate the impact of the Kubelet and the kernel. The first test measured Kubelet overhead by comparing clusters with the feature gate on and off while the kernel already tracked PSI. The second test measured kernel overhead by enabling PSI at the kernel level versus leaving it off. Both tests ran on real production‑like workloads to ensure the results reflected true operational conditions.
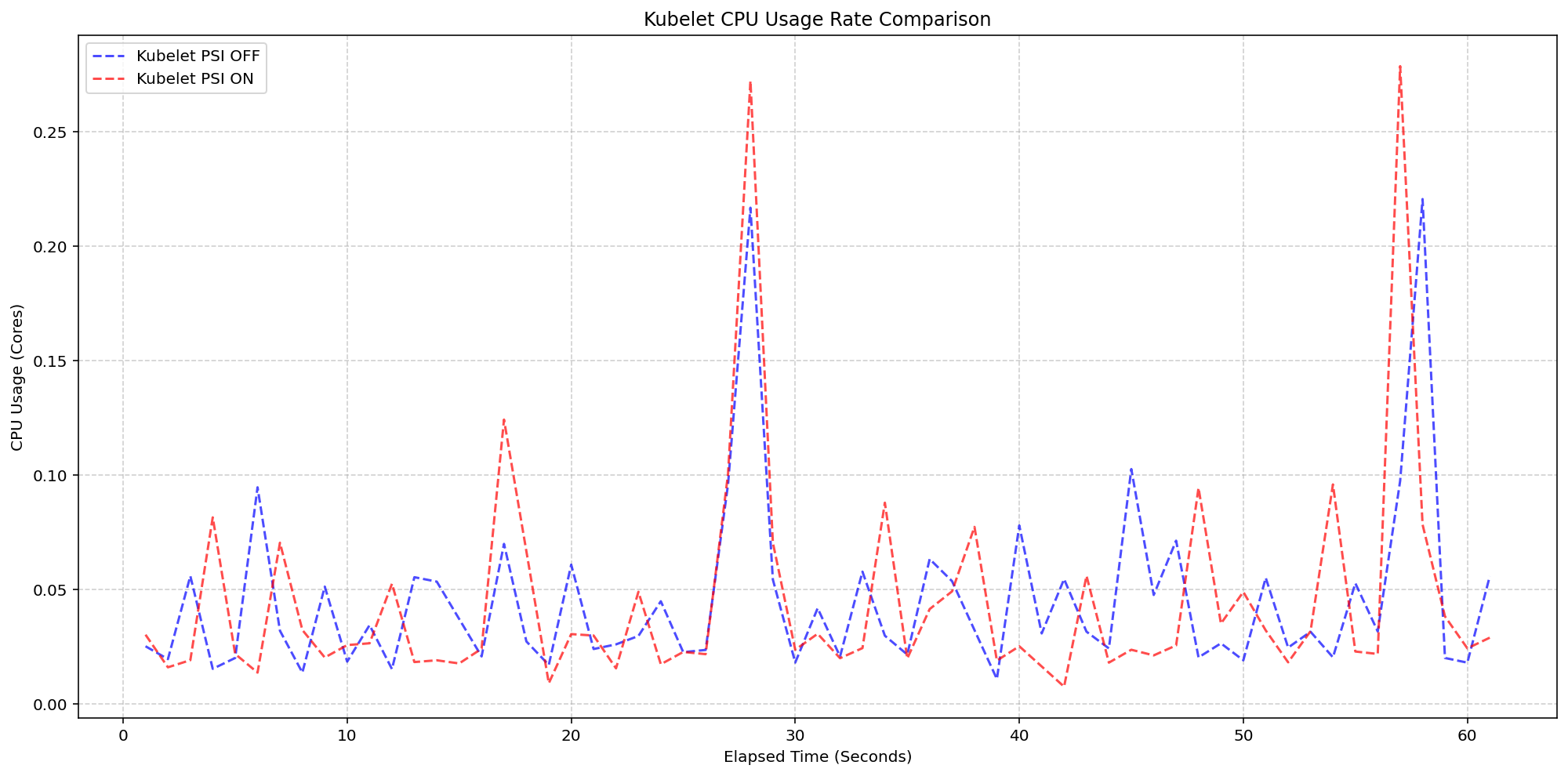
5. Kubelet Overhead Is Almost Negligible
In the first scenario, the kernel was already tracking PSI (psi=1), but the Kubelet’s feature gate for exposing those metrics was toggled. On 4‑core machines, the CPU usage of the kubelet was compared. The synchronized bursts in the graphs were practically identical in both magnitude and frequency—whether PSI metrics were being queried or not. The added overhead stayed within 0.1 cores (about 2.5% of total node capacity). This confirms that the Kubelet’s collection logic is extremely lightweight, blending into standard housekeeping cycles without any noticeable impact. Operators can enable the feature without fear of degrading node performance.
6. Kernel Overhead Is Also Minimal and Predictable
The second scenario compared a cluster with kernel PSI tracking enabled against one where it was off. The system CPU usage in the PSI‑enabled cluster followed the same pattern as the disabled cluster, with only a slight increase—around 2.5 cores on the tested machines. This small lift is the cost the kernel pays to maintain pressure stalls. Crucially, the overhead does not scale with the number of cgroups queried; it’s a fixed cost once the feature is on. The testing proved that for most modern hardware, the kernel overhead is imperceptible. Given the enormous benefit of accurate pressure signals, this trade‑off is a clear win for production environments.
7. Graduation to GA Means Production‑Safe Adoption
With v1.36, PSI metrics are no longer experimental or alpha. They have passed the rigorous graduation criteria set by the Kubernetes community, including backward compatibility, comprehensive documentation, and the performance tests described above. This means you can safely enable the feature in production clusters without worrying about stability. The stable API guarantees that the metrics will be reliable and consistent across releases. For SREs and platform engineers, this is a powerful new tool for capacity planning, autoscaling, and root‑cause analysis. By pairing PSI with existing utilization metrics, you get a complete picture of resource health—one that catches issues before they become outages.
Kubernetes v1.36's graduation of PSI metrics is a testament to the community's commitment to observability that actually works. By moving beyond raw utilization to measure stalled tasks, PSI gives operators the signal they need to make smarter scaling decisions. The low overhead, both at the kernel and Kubelet levels, means you can enable it without sacrificing performance. Whether you're managing a small cluster or a massive multi‑tenant environment, PSI provides the clarity to keep your workloads running smoothly. Enable it today and start seeing the contention your other metrics miss.