How Poetiq's Meta-System Boosts LLM Coding Performance Without Changing the Model
In a significant breakthrough for artificial intelligence research, Poetiq has announced that its Meta-System achieved a new state-of-the-art result on LiveCodeBench Pro (LCB Pro), a demanding coding benchmark. What makes this achievement remarkable is that the system automatically built and optimized its own inference harness without fine-tuning any underlying model or accessing internal model parameters. The harness improved every large language model (LLM) tested, demonstrating a model-agnostic approach that could reshape how AI coding systems are deployed.
Understanding LiveCodeBench Pro
LiveCodeBench Pro is not just another benchmark—it is specifically designed to resist data contamination and overfitting, two persistent issues in AI evaluation. Problems are sourced from major competitive programming competitions, and ground-truth code is withheld from public datasets. Instead, solutions are validated against a comprehensive testing framework that checks not only for correct output but also for memory and runtime constraints. The benchmark undergoes continuous updates, ensuring it remains relevant and challenging.
LCB Pro focuses exclusively on C++ challenges, emphasizing creative coding and the ability to generate high-quality, performant procedural logic. This sets it apart from other benchmarks like SWEBench, which evaluate tool usage or bug-fixing workflows. Problems are categorized into Easy, Medium, and Hard based on human solve rates from competitive programming, providing a clear difficulty gradient.
Poetiq's Strategic Framing: Three LLM Task Categories
This publication marks Poetiq's third publicly reported benchmark, and the choice of LCB Pro was intentional. The research team categorizes LLM capabilities into three distinct task types: reasoning challenges (their benchmark is ARC-AGI), retrieval challenges (Humanity's Last Exam, or HLE), and coding challenges. Coding, they argue, is the most commercially pervasive AI application today, blending reasoning, retrieval, and the generation of specialized procedural logic.
Poetiq set three specific objectives for their coding initiative:
- Prove that an intelligent harness can boost efficacy without fine-tuning or special model access.
- Validate the Meta-System's capacity for recursive self-improvement in creating that harness automatically.
- Demonstrate that the resulting harness is model-agnostic and can be applied to any model without modification.
According to their results, all three objectives were satisfied.
What Is a Harness, and Why Does It Matter?
In this context, a harness refers to the infrastructure that feeds inputs to an LLM, manages its outputs, and enforces constraints like token limits, formatting, and sampling parameters. Poetiq's Meta-System automatically designs and optimizes this harness—tuning how questions are presented, how the model's reasoning is structured, and how final answers are extracted and validated. Crucially, the harness is entirely external to the model; it requires no access to weights, gradients, or training data.

Think of a harness as the scaffolding around a model. By optimizing the scaffolding, Poetiq found that every tested model performed better on LCB Pro, even without any changes to the model itself. The harness was specifically optimized on Gemini 3.1 Pro, but the same harness improved other models just as effectively—confirming its model-agnostic nature.
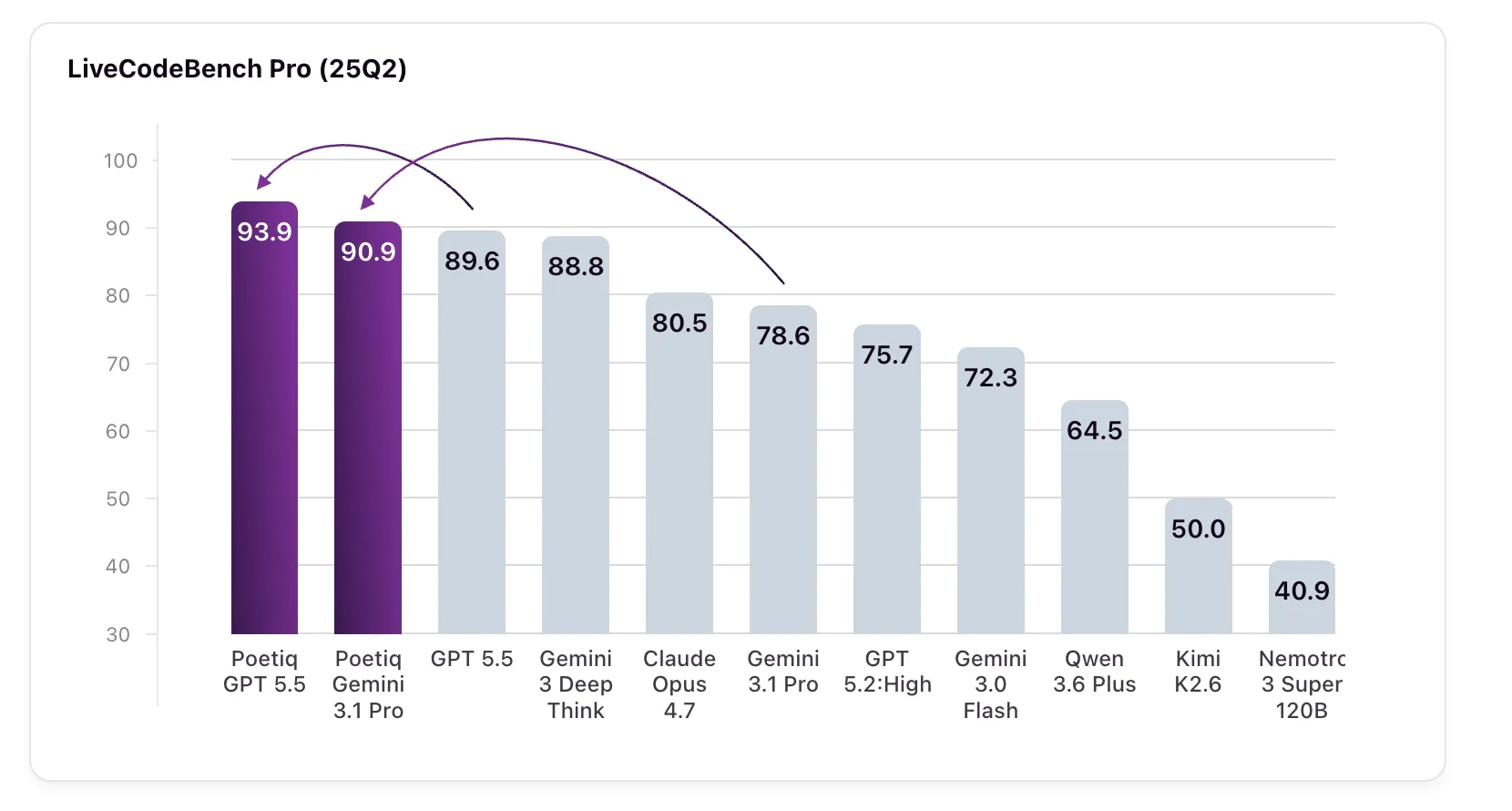
Results and Implications
The numbers speak for themselves. GPT 5.5 High, when run with Poetiq's harness, scored 93.9% on LCB Pro (Q2 2025), up from a baseline of 89.6%. Gemini 3.1 Pro, the model for which the harness was specifically optimized, jumped from 78.6% to 90.9%—surpassing Google's own Gemini 3 Deep Think (88.8%), a model not even accessible via API for external verification.
These gains were achieved purely through the harness; no fine-tuning or model modifications were performed. The harness automatically adapts the inference process, including how the model chunks problems, generates intermediate reasoning, and formats code. The system also demonstrated recursive self-improvement: the Meta-System analyzed its own harness performance and iteratively refined it without human intervention.
The Broader Picture
Poetiq's results challenge the prevailing assumption that improving LLM performance requires bigger models, more data, or costly fine-tuning. Instead, they show that intelligent orchestration of existing models can yield substantial gains. This approach is particularly valuable for organizations that rely on black-box APIs—where model internals are inaccessible—and want to squeeze more performance out of a given model.
The fact that the harness is model-agnostic means it can be deployed across different LLMs without customization, simplifying integration and reducing engineering overhead. As coding becomes an ever more central AI use case, techniques like Poetiq's Meta-System could become standard practice, offering a cost-effective path to better results.
With this breakthrough, Poetiq has demonstrated that the next frontier in AI performance may not be in the models themselves, but in the systems that deploy them.